
引言
鱼皮的 AI爆款文章创作器 项目是一个很好的学习基于 Go 语言打造多智能体 + 多模态内容生成的项目。该项目集合多智能体编排和 AI 工作流等最新的 AI 编程技术,配合前端代码组建完整的 Web 项目。阅读源码,了解他的设计理念和编程思想,对未来传统后端开发转 AI Agent 开发或者全栈开发做好准备。
项目源码点击这里,本文将借助腾讯自研 AI IDE 插件 CodeBuddy 快速学习该项目,理清项目结构。
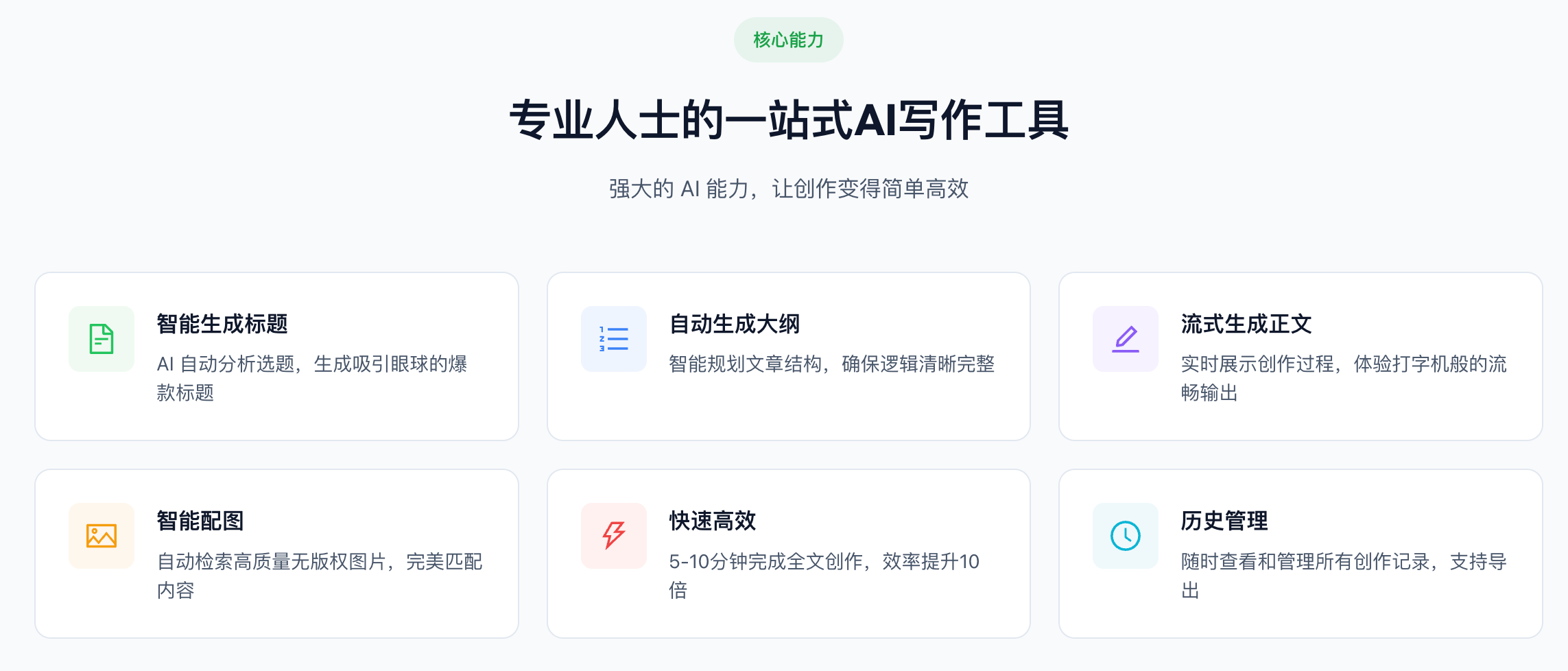
该项目主要有五大核心功能:
- 多智能体协作创作
- 多种配图方式
- 三阶段人机协作
- VIP 会员体系
- 智能体可观测性
首先是多智能体协作创作,用户可以输入选题,决定文章内容大体方向,后续由 5 个智能体协作完成从标题、大纲、正文到配图的完整创作流程,在生成过程中为了让用户及时获得反馈,采用 SSE 流式输出,实时可见 AI 的创作过程;然后是多种配图方式,支持 Pexels 图库搜索、Mermaid 流程图、Iconify 图标、表情包搜索、SVG 概念示意图、Nano Banana AI 生图等多种配图方式,通过策略模式实现灵活扩展;接着是三阶段人机协作,采用 “Human in the loop” 的设计理念,用户可以在标题选择、大纲编辑两个阶段与 AI 协作,获得更满意的创作结果;再然后是 VIP 会员体系,集成 Stripe 国际支付,实现 VIP 会员开通、配额差异化管理、配图方式权限控制等完整的会员体系;最后是智能体可观测性,在实现中自动记录智能体执行日志,提供执行耗时统计、成功率分析、用户活跃度等数据统计功能。
本项目的学习重点是在智能体集群中,各个智能体的分工和配合是如何实现的,不同于之前的 GoNexus 项目简单的调用一次大模型 API。(GoNexus 项目完整加入了 RAG、MCP 功能,但是也只停留在单次大模型 API 调用上实现 AI 对话)
除此之外,项目还涉及 SSE 流式推送、策略模式扩展、异步任务编排、状态机设计、Stripe 支付集成等多个部分,都值得学习一下。好了,接下来我们就开始吧。
一、项目目录分析
拿到项目的第一件事是先理清项目的目录结构,了解每个目录包含的功能。
对于 Go 后端项目,先找主函数 main.go,这是项目的起始入口,在 cmd/server 目录下;
然后依次找到 handler、service、dao 这三层,对应 Java 开发中的 MVC 三层架构:其中 handler 就是暴露给前端的接口,和 contorller 层功能类似,service 目录下的文件是真正的核心业务逻辑,dao 目录(或者叫 store 目录)下的文件是对应数据库各张表的 crud 方法,与 Java 中的 DAO/Mapper 层功能类似;
最后找到 model、middleware、common、config:其中 model 目录下存放的是数据模型结构,包括对应的数据库表的结构体、层之间传递的数据(DTO)结构体以及传给前端所需的数据(VO)结构体,middleware 包存放的是中间件,比如用户所需的权限验证 auth,前后端解决跨域问题的 cors,用户登录信息需要的 session(在 GoNexus 项目中涉及的中间件只有用于用户登录验证 token 的 auth,解决跨域问题的 cors 被集成到 service 层聊天方法中了),common 包实现了一些被其它包需要反复引用的共用方法,防止出现循环引用,config 包实现了项目所需要的各种配置。
go-backend/
├── cmd/server/main.go # 入口
├── internal/ # 🔒 私有代码(不可被外部导入)
│ ├── handler/ # ← 处理器层(类似 Controller)
│ │ ├── user.go
│ │ ├── article.go
│ │ ├── payment.go
│ │ └── ...
│ ├── service/ # ← 业务逻辑层
│ │ ├── user.go
│ │ ├── article.go
│ │ ├── article_agent.go # AI 智能体业务
│ │ ├── pexels.go # 图片搜索服务
│ │ └── ...
│ ├── store/ # ← 数据访问层(类似 DAO)
│ │ ├── user.go
│ │ ├── article.go
│ │ └── ...
│ ├── model/ # ← 数据模型(实体 + 请求/响应 VO)
│ ├── common/ # ← 公共工具(错误码、常量、SSE)
│ ├── config/ # ← 配置
│ ├── middleware/ # ← 中间件
│ ├── app/ # ← 应用程序初始化
│ │ └── app.go
│ └── agent/ # ← AI 智能体(本项目的特色)
└── docs/ # Swagger 文档
纵观整个项目目录,除了刚才提到的常见目录,还多了一个名为 app 和 agent 的目录。app 目录是负责对整个后端程序需要的实例初始化的(有时候这些初始化方法也写在 main.go 中,像 GoNexus 就写在了 main.go 中)。而 agent 目录是为了将 service 层的核心业务逻辑与 AI agent 调用实现解耦,所以在 service 和 AI 之间加入了一层抽象 agent,详细目录如下:
internal/
├── handler/ # 处理 HTTP 请求
├── service/ # 业务编排(创建任务、状态管理)
├── agent/ # ⭐ AI 智能体层(调用大模型、生成内容)
│ ├── agents/ # 具体智能体(标题生成器、大纲生成器、正文生成器...)
│ ├── context/ # 流式处理上下文
│ ├── parallel/ # 并行执行(如多张图同时生成)
│ ├── agent.go # 执行智能体任务接口
│ └── orchestrator.go # 多智能体编排器
└── store/ # 数据持久化
项目整体数据流如下:
HTTP请求 → Handler → Service → Store(GORM) → MySQL
↓ ↓ ↓ ↓
参数绑定 身份认证 业务编排 ORM操作
Session获取 权限检查 配额管理 返回model
↓ ↓ ↓ ↓
└──────────┴─────────┴────────────↓
↓
model 转换 (举例 ToArticleInfo / ToLoginUser)
↓
BaseResponse{code, data, message}
↓
c.JSON(200, response)
二、数据库表设计
用户表 user
create table if not exists user
(
id bigint auto_increment comment 'id' primary key,
userAccount varchar(256) not null comment '账号',
userPassword varchar(512) not null comment '密码',
userName varchar(256) null comment '用户昵称',
userAvatar varchar(1024) null comment '用户头像',
userProfile varchar(512) null comment '用户简介',
userRole varchar(256) default 'user' not null comment '用户角色:user/admin',
quota int default 5 not null comment '剩余配额',
vipTime datetime null comment '成为会员时间',
editTime datetime default CURRENT_TIMESTAMP not null comment '编辑时间',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
UNIQUE KEY uk_userAccount (userAccount),
INDEX idx_userName (userName)
) comment '用户' collate = utf8mb4_unicode_ci;文章表 article
create table if not exists article
(
id bigint auto_increment comment 'id' primary key,
taskId varchar(64) not null comment '任务ID(UUID)',
userId bigint not null comment '用户ID',
topic varchar(500) not null comment '选题',
userDescription text null comment '用户补充描述',
enabledImageMethods json null comment '允许的配图方式列表',
style VARCHAR(20) null comment '文章风格:tech/emotional/educational/humorous',
mainTitle varchar(200) null comment '主标题',
subTitle varchar(300) null comment '副标题',
titleOptions json null comment '标题方案列表(3-5个方案)',
outline json null comment '大纲(JSON格式)',
content text null comment '正文(Markdown格式)',
fullContent text null comment '完整图文(Markdown格式,含配图)',
coverImage varchar(512) null comment '封面图 URL',
images json null comment '配图列表(JSON数组,包含封面图 position=1)',
status varchar(20) default 'PENDING' not null comment '状态:PENDING/PROCESSING/COMPLETED/FAILED',
phase VARCHAR(50) default 'PENDING' comment '当前阶段:PENDING/TITLE_GENERATING/TITLE_SELECTING/OUTLINE_GENERATING/OUTLINE_EDITING/CONTENT_GENERATING',
errorMessage text null comment '错误信息',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
completedTime datetime null comment '完成时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
UNIQUE KEY uk_taskId (taskId),
INDEX idx_userId (userId),
INDEX idx_status (status),
INDEX idx_createTime (createTime),
INDEX idx_userId_status (userId, status)
) comment '文章表' collate = utf8mb4_unicode_ci;智能体执行日志记录表 agent_log
create table if not exists agent_log
(
id bigint auto_increment comment 'id' primary key,
taskId varchar(64) not null comment '任务ID',
agentName varchar(50) not null comment '智能体名称',
startTime datetime not null comment '开始时间',
endTime datetime null comment '结束时间',
durationMs int null comment '耗时(毫秒)',
status varchar(20) not null comment '状态:SUCCESS/FAILED',
errorMessage text null comment '错误信息',
prompt text null comment '使用的Prompt',
inputData json null comment '输入数据(JSON格式)',
outputData json null comment '输出数据(JSON格式)',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
INDEX idx_taskId (taskId),
INDEX idx_agentName (agentName),
INDEX idx_status (status),
INDEX idx_createTime (createTime)
) comment '智能体执行日志表' collate = utf8mb4_unicode_ci;支付记录表 payment_record
CREATE TABLE IF NOT EXISTS payment_record (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
userId BIGINT NOT NULL COMMENT '用户ID',
stripeSessionId VARCHAR(128) COMMENT 'Stripe Checkout Session ID',
stripePaymentIntentId VARCHAR(128) COMMENT 'Stripe 支付意向ID',
amount DECIMAL(10,2) NOT NULL COMMENT '金额(美元)',
currency VARCHAR(8) DEFAULT 'usd' COMMENT '货币',
status VARCHAR(32) NOT NULL COMMENT '状态:PENDING/SUCCEEDED/FAILED/REFUNDED',
productType VARCHAR(32) NOT NULL COMMENT '产品类型:VIP_PERMANENT',
description VARCHAR(256) COMMENT '描述',
refundTime DATETIME NULL COMMENT '退款时间',
refundReason VARCHAR(512) NULL COMMENT '退款原因',
createTime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updateTime DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
INDEX idx_userId (userId),
INDEX idx_stripeSessionId (stripeSessionId),
INDEX idx_status (status),
INDEX idx_createTime (createTime)
) COMMENT '支付记录表' COLLATE = utf8mb4_unicode_ci;二、用户模块
这部分比较常规,先跳过后续再补充
三、AI 创作模块
先从 handler/article.go 文件开始梳理。
┌─────────────────────────────────────────────────────────────────────┐
│ ArticleHandler 方法分类 │
├───────────┬──────────────────┬──────────────────────────────────────┤
│ 分类 │ 方法名 │ 功能 │
├───────────┼──────────────────┼──────────────────────────────────────┤
│ ① 创建 │ Create │ 创建文章任务(含配额检查) │
│ ② 查询 │ Get │ 获取文章详情 │
│ │ List │ 分页查询文章列表 │
│ │ GetProgress │ SSE 实时获取生成进度 │
│ │ GetExecutionLogs │ 获取执行日志 │
│ ③ 确认 │ ConfirmTitle │ 用户确认标题 + 补充描述 │
│ │ ConfirmOutline │ 用户确认/编辑大纲 │
│ ④ AI 辅助 │ AiModifyOutline │ AI 帮用户修改大纲 │
│ ⑤ 删除 │ Delete │ 删除文章 │
└───────────┴──────────────────┴───────────────────────────────────────┘
article.go 文件中包含 9 个方法,按照业务功能可以分为 5 大类,具体负责的逻辑如上表所示。
下图展示了从用户选题开始,经过AI 生成标题、AI 生成大纲、AI 生成正文、AI 生成配图等多步操作产生一篇完整文章的生命周期。
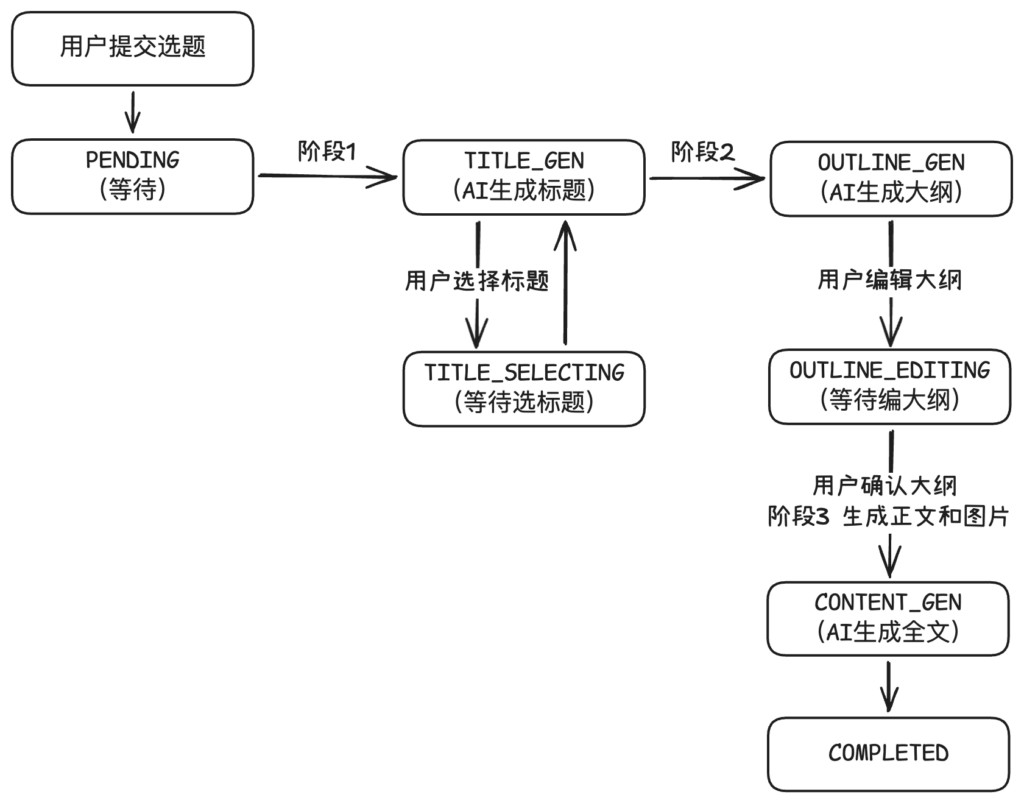
接下来将展示各方法的详细设计流程
1. Create 创建文章任务,入口:POST /api/article/create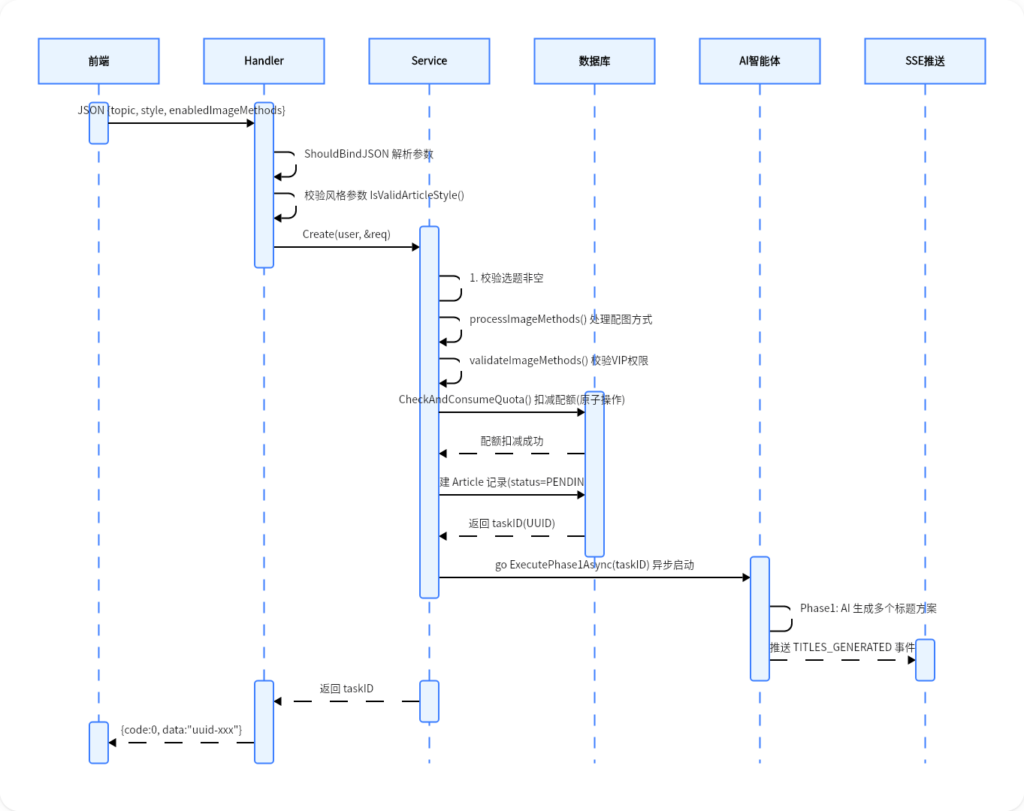
核心业务逻辑在 service 层的 Create 方法中。首先调用 processImageMethod 方法,根据用户类型(普通用户/ VIP 用户)返回用户可以使用哪些配图方式,代码如下:
// processImageMethods 处理配图方式
// 如果用户未选择,给普通用户设置默认的非 VIP 方式,VIP 和管理员不限制
func (s *ArticleService) processImageMethods(methods []string, user *model.User) []string {
// 如果用户已选择,直接返回
if len(methods) > 0 {
return methods
}
// VIP 和管理员:不限制,返回 nil 表示支持所有方式
if s.isVipOrAdmin(user) {
return nil
}
// 普通用户:返回默认的非 VIP 方式
return []string{
common.ImageMethodPexels,
common.ImageMethodMermaid,
common.ImageMethodIconify,
common.ImageMethodEmojiPack,
}
}该方法在处理配图方式时,用户如果是 VIP 或管理员身份,通过返回 nil 来表示支持所有配图方式,而普通用户仅支持 Pexels、Mermaid、Iconify、EmojiPack 四种处理方式。
然后调用 validateImageMethods 方法,根据用户类型校验是否可以使用选中的图片处理方式,代码如下:
// validateImageMethods 校验配图方式权限
// 普通用户不能使用 NANO_BANANA 和 SVG_DIAGRAM
func (s *ArticleService) validateImageMethods(methods []string, user *model.User) error {
if len(methods) == 0 {
return nil
}
// VIP 和管理员无限制
if s.isVipOrAdmin(user) {
return nil
}
// 普通用户限制
for _, method := range methods {
if method == common.ImageMethodNanoBanana || method == common.ImageMethodSVGDiagram {
return common.ErrNoAuth.WithMessage("高级配图功能(AI 生图、SVG 图表)仅限 VIP 会员使用")
}
}
return nil
}然后调用配额检查方法 CheckAndConsumeQuota ,该方法是同步阻塞的,从 SQL 语句层面执行原子操作确保有配额才会创建任务。代码如下:
// CheckAndConsumeQuota 检查并消耗配额(原子操作)
// 如果配额不足会返回错误
func (s *QuotaService) CheckAndConsumeQuota(user *model.User) error {
// 管理员和 VIP 用户跳过检查
if s.isAdmin(user) || s.isVIP(user) {
return nil
}
// 使用原子更新:检查与消费合并为一个原子操作
affectedRows, err := s.userStore.DecrementQuota(user.ID)
if err != nil {
return common.ErrSystem
}
if affectedRows == 0 {
// 影响行数为0,说明配额不足(已被其他请求消耗)
return common.ErrOperation.WithMessage("配额不足,无法创建文章")
}
log.Printf("用户配额检查并消耗成功, userId=%d", user.ID)
return nil
}该方法中核心部分是 DecrementQuota 方法,代码如下:
// DecrementQuota 原子扣减用户配额
// 使用 quota > 0 条件确保并发安全,避免超扣
// 返回影响行数:1表示成功,0表示配额不足
func (s *UserStore) DecrementQuota(userID int64) (int64, error) {
result := s.db.Exec("UPDATE user SET quota = quota - 1 WHERE id = ? AND quota > 0", userID)
return result.RowsAffected, result.Error
}以 SQL 语句 UPDATE user SET quota = quota – 1 WHERE id = ? AND quota > 0 使用 quota > 0 为判定条件确保并发安全,避免超扣。UPDATE 语句的并发处理这篇文章详细介绍了为什么只需要使用 quota > 0 就可以确保并发安全,并延伸了乐观锁和悲观锁各自的应用场景。
配额扣减成功后,创建文章数据,构建 taskID ,将能使用的图片生成方法字符串数组 finalImageMethods []string 转成 json 格式的字符串 methodsJSON 写入数据库底表。接着是最重要的部分,启动一个协程负责 AI 标题生成,在协程执行期间,先立刻向前端返回 taskID,前端拿到 taskID 后,调用 GetProgress 接口方法通过 SSE 实时获取文章生成数据。
接下来详细看一下开启的协程内部逻辑,go ExecutePhase1Async()。
代码如下:
// ExecutePhase1Async 阶段1:异步生成标题方案
func (s *ArticleService) ExecutePhase1Async(taskID, topic, style string) {
useOrchestrator := s.cfg.Agent.Orchestrator.Enabled
log.Printf("阶段1异步任务开始, taskId=%s, topic=%s, style=%s, 使用多智能体编排=%v",taskID, topic, style, useOrchestrator)
// 更新状态和阶段
_ = s.store.UpdateStatus(taskID, model.StatusProcessing, nil)
_ = s.UpdatePhase(taskID, model.PhaseTitleGenerating)
// 创建状态对象
state := &model.ArticleState{
TaskID: taskID,
Topic: topic,
Style: style,
Phase: model.PhaseTitleGenerating,
}
// 执行智能体1:生成标题方案(根据配置选择执行方式)
ctx := context.Background()
var err error
if useOrchestrator {
err = s.orchestrator.ExecutePhase1(ctx, state)
} else {
err = s.agentSvc.ExecutePhase1(ctx, state)
}
if err != nil {
log.Printf("阶段1异步任务失败, taskId=%s, error=%v", taskID, err)
// 更新状态为失败
errMsg := err.Error()
_ = s.store.UpdateStatus(taskID, model.StatusFailed, &errMsg)
// 推送错误消息
s.sseManager.Send(taskID, map[string]interface{}{
"type": common.SSEMsgError,
"message": errMsg,
})
s.sseManager.Complete(taskID)
return
}
// 保存标题方案到数据库
if err := s.SaveTitleOptions(taskID, state.TitleOptions); err != nil {
log.Printf("保存标题方案失败, taskId=%s, error=%v", taskID, err)
errMsg := "保存标题方案失败"
_ = s.store.UpdateStatus(taskID, model.StatusFailed, &errMsg)
return
}
// 更新阶段为等待选择标题
_ = s.UpdatePhase(taskID, model.PhaseTitleSelecting)
// 推送标题方案生成完成消息
s.sseManager.Send(taskID, map[string]interface{}{
"type": common.SSEMsgTitlesGenerated,
"titleOptions": state.TitleOptions,
})
log.Printf("阶段1异步任务完成, taskId=%s, optionsCount=%d", taskID, len(state.TitleOptions))
}是否启用多智能体编排模式已经在 config.yaml 配置文件中写好,执行 useOrchestrator := s.cfg.Agent.Orchestrator.Enabled 获取配置信息。
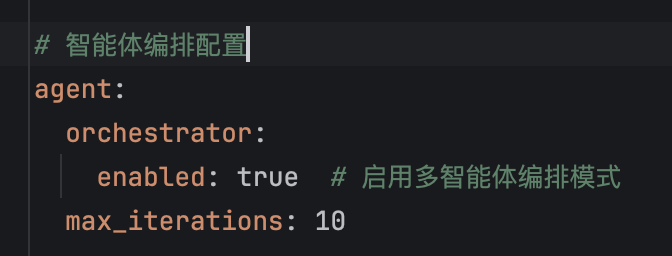
UpdateStatus 方法将此刻的文章状态设置为 PROCESSING,UpdatePhase 方法将此刻的文章阶段设置为 TITLE_GENERATING,全部的状态和阶段设置如下图所示。

文章状态包括 PENDING 等待处理,PROCESSING 进行中,COMPLETED 已完成,FAILED 已失败共四种状态。
文章阶段包括 PENDING 等待处理,TITLE_GENERATING 生成标题中,TITLE_SELECTING 等待选择标题,OUTLINE_GENERATING 生成大纲中,OUTLINE_EDITING 等待编辑大纲,CONTENT_GENERATING 生成正文中。
问:在更新文章 state 和 phase 时为什么要采用 _ = 这种方式忽略错误?
答:因为在异步任务内部,如果状态更新失败会阻塞主流程,所以只需要记录一些日志即可。
// 执行智能体1:生成标题方案(根据配置选择执行方式)
ctx := context.Background()
var err error
if useOrchestrator {
err = s.orchestrator.ExecutePhase1(ctx, state)
} else {
err = s.agentSvc.ExecutePhase1(ctx, state)
}根据配置方式选择多智能体编排方案,执行 orchestrator.ExecutePhase1 方法。
func (o *ArticleAgentOrchestrator) ExecutePhase1(ctx context.Context, state *model.ArticleState) error
1. 执行标题生成智能体的 Execute 方法
2. 向前端推送 AI 生成的文章标题信息
agent/orchestrator.go 文件的 ArticleAgentOrchestrator 结构体实现了 service/article.go 文件中的 AgentOrchestrator 接口。其中 AgentOrchestrator 是智能体编排器接口,声明了三个方法 ExecutePhase1、ExecutePhase2、ExecutePhase3,由结构体 ArticleAgentOrchestrator 依次实现,分别代表 AI 生成文章过程中的三个阶段,分别是生成标题方案阶段、生成大纲阶段、生成正文+配图阶段。
位于 agent/agent.go 文件中的 agent 接口声明了方法 Execute,五个不同的智能体结构体(titleGenerator/outlineGenerator/contentGenerator/imageAnalyzer/parallelImageGenerator)分别实现了该接口的 Execute 方法。通过策略模式由 ArticleAgentOrchestrator 负责上下文,通过不同策略在不同阶段进行文章的创作执行。
这里先来看在第一个阶段,即生成标题方案阶段涉及的智能体 1 ——titleGenerator 的 Execute 方法的逻辑。方法位于 agent/agents/title_generate.go 文件中。
func (a *TitleGeneratorAgent) Execute(ctx context.Content, state *model.ArticleState) error
该方法负责执行标题生成任务。
1. 创建智能体日志记录
2. 通过 defer + 闭包函数确保智能体日志一定会被保存
3. 构建 prompt ,将用户选择的主题和文章风格进行填充
你是一位爆款文章标题专家,擅长创作吸引人的标题。
根据以下选题,生成 3-5 个爆款文章标题方案:
选题:{topic}
要求:
1. 每个方案包含主标题和副标题
2. 主标题要包含数字、情绪化词汇,吸引眼球
3. 副标题要补充说明,增强吸引力
4. 标题要简洁有力,不超过30字
5. 不同方案要有不同的切入角度
6. 符合新媒体爆款文章的风格
请直接返回 JSON 格式,不要有其他内容:
[
{
"mainTitle": "主标题1",
"subTitle": "副标题1"
},
{
"mainTitle": "主标题2",
"subTitle": "副标题2"
},
{
"mainTitle": "主标题3",
"subTitle": "副标题3"
}
]4. 基于 https://github.com/tmc/langchaingo/ 包调用 LLM 模型(LLM 初始化也是基于 langchaingo 的 openai 包实现的,底层模型用的 QWEN)返回 AI 生成的标题方案数据
5. 解析标题方案列表,将标题方案数据填充到共享传输结构体 ArticleState 中用于后续智能体执行任务阶段做数据传输,同时更改智能体日志信息以便保存最新日志
ArticleAgentOrchestrator 结构体的 ExecutePhase1 方法在成功执行了 Execute 方法后实现了文章标题的生成,然后通过 SSE 完成向前端推送标题信息的功能,前端经过 GetProgress 方法实时获取这些标题信息,增强用户的反馈。
这里简单看一下如何通过 SSE 完成后端数据实时发送给前端,前端实时接收的逻辑。
在 ExecutePhase1 方法中执行完 Execute 方法后又执行了 sendMessage 方法。
// 推送完成消息
o.sendMessage(state.TaskID, map[string]interface{}{
"type": common.SSEMsgAgent1Complete,
"titleOptions": state.TitleOptions,
})func (o *ArticleAgentOrchestrator) sendMessage(taskID string, data interface{})
这个方法是对 data 进行 type 转换
// 将数据转换为 JSON 字符串(如果需要)
switch v := data.(type) {
case map[string]interface{}:
// 已经是 map,直接发送
o.sseManager.Send(taskID, v)
case string:
// 如果是字符串,尝试解析为 JSON
var jsonData map[string]interface{}
if err := json.Unmarshal([]byte(v), &jsonData); err == nil {
o.sseManager.Send(taskID, jsonData)
} else {
// 如果解析失败,包装为简单消息
o.sseManager.Send(taskID, map[string]interface{}{"message": v})
}
default:
log.Printf("警告:不支持的消息类型: %T", v)
}接下来将对 SSE 进行详细解读,深入前后端实时获取数据的交互机制。
// SSEManager SSE 连接管理器
type SSEManager struct {
clients map[string]chan string
mu sync.RWMutex
}
// NewSSEManager 创建 SSE 管理器
func NewSSEManager() *SSEManager {
return &SSEManager{
clients: make(map[string]chan string),
}
}
// Register 注册 SSE 客户端
func (m *SSEManager) Register(taskID string) chan string {
m.mu.Lock()
defer m.mu.Unlock()
ch := make(chan string, 100) // 缓冲通道
m.clients[taskID] = ch
return ch
}
// Unregister 注销 SSE 客户端
func (m *SSEManager) Unregister(taskID string) {
m.mu.Lock()
defer m.mu.Unlock()
if ch, ok := m.clients[taskID]; ok {
close(ch)
delete(m.clients, taskID)
}
}SSEManager 通过 Channel 转发数据,每一个 taskID 都对应一个 Channel,结合读写锁保护 clients map 的并发读写安全,在初始化 SSE 客户端时将 chan 设置为 chan string 缓冲为 100,即使前端消费慢一点,也能缓存 100 条消息。
// Send 发送消息
func (m *SSEManager) Send(taskID string, data interface{}) {
m.mu.RLock()
ch, ok := m.clients[taskID]
m.mu.RUnlock()
if !ok {
return
}
// 将数据转为 JSON
jsonData, err := json.Marshal(data)
if err != nil {
return
}
// 非阻塞发送
select {
case ch <- string(jsonData):
case <-time.After(5 * time.Second):
// 超时则放弃
}
}在 Send 方法中采用非阻塞 select + channel 的方式将数据进行发送,如果 channel 满了也不会阻塞该智能体,避免了拖慢 LLM 流式生成。
然后再来看看 GetProgress 接口方法的逻辑
func (h *ArticleHandler) GetProgress(c *gin.Context)
1. 设置 SSE 必需的响应头,解决跨域请求和禁止浏览器缓存的设置
2. 调用 SSEManager 的 Register 方法连接当前 taskID 专属的 channel,defer 机制确保请求结束后 SSE 连接关闭
3. 启动流式推送循环
对于第三步启动流式推送循环中,gin 框架支持 SSE 流式,代码如下:
// 流式推送
c.Stream(func(w io.Writer) bool {
select {
case msg, ok := <-messageChan:
if !ok {
return false
}
c.SSEvent("message", msg)
c.Writer.Flush()
return true
case <-c.Request.Context().Done():
// 客户端断开连接
return false
case <-time.After(30 * time.Minute):
// 超时
return false
}
})从创建的 SSE 管道 messageChan 中读取,如果读取到 msg,则按 SSE 格式写入,并立刻刷新到浏览器,继续等待下一条推送的消息。如果出现未能读取到 msg、客户端断开连接、超时等情况就会返回 false.
c.SSEvent(“message”, msg) 实际写出的内容以大纲内容为例:
event: message
data: {"type":"AGENT2_STREAMING","content":"根据最新研究..."}
event: message
data: {"type":"AGENT2_STREAMING","content":",大语言模型(LLM)"}
event: message
data: {"type":"OUTLINE_GENERATED","outline":[{...}]}
每条消息之间用 \n\n 分隔,这是 SSE 协议的标准格式。
接下来看前端如何建立连接并实时消费数据
第一步:创建任务后立即建立 SSE 连接
前端代码 src/pages/article/ArticleCreatePage.vue 的 startCreate 方法,核心代码如下:
const startCreate = async () => {
// 1️⃣ 先调 POST /api/article/create 创建任务
const res = await createArticle({ topic: topic.value, ... })
const newTaskId = res.data.data // 获得 taskId
taskId.value = newTaskId
// 2️⃣ ⭐ 立即建立 SSE 连接(不等用户操作!)
eventSource = connectSSE(taskId.value, {
onMessage: handleSSEMessage, // 收到消息的回调
onError: handleSSEError, // 出错的回调
onComplete: handleSSEComplete, // 完成的回调
})
}第二步:connectSSE 工具函数——封装 EventSource API
前端代码 src/utils/sse.ts 的 connectSSE 方法,核心代码如下:
export const connectSSE = (taskId: string, options: SSEOptions): EventSource => {
const { onMessage, onError, onComplete } = options
// 🔑 核心:浏览器原生 EventSource API 自动处理:
// - HTTP 连接保持
// - 断线自动重连
// - 解析 "data: ...\n\n" 格式
const eventSource = new EventSource(`/api/article/progress/${taskId}`)
// 浏览器自动触发此回调每当收到一条 SSE 消息
eventSource.onmessage = (event) => {
try {
const message: SSEMessage = JSON.parse(event.data)
// event.data = '{"type":"AGENT2_STREAMING","content":"根据最新..."}'
onMessage(message) // 转交给页面的处理函数
// 检查是否是终止信号
if (message.type === 'ALL_COMPLETE' || message.type === 'ERROR') {
eventSource.close() // 关闭连接
onComplete?.()
}
} catch (error) {
console.error('SSE 消息解析失败:', error)
}
}
eventSource.onerror = (error) => {
console.error('SSE 连接错误:', error)
onError?.(error)
eventSource.close()
}
return eventSource
}EventSource vs 普通 fetch/ajax 的区别:
| 特性 | fetch/axios | EventSource(SSE) |
| 连接方式 | 请求->响应->断开 | 长连接,持续接收 |
| 数据方向 | 单次请求单次响应 | 服务器主动推送多次 |
| 重连机制 | 无 | 内置自动重连 |
| 数据格式 | JSON/任意 | data: …\n\n 文本流 |
| 适用场景 | CRUD操作 | 实时通知、进度推送 |
第三步:handleSSEMessage——消息分发中心
前端代码 src/pages/article/ArticleCreatePage.vue 的 handleSSEMessage 方法。整个前端最核心的方法,一个巨大的 switch/case 根据消息类型驱动整个 UI 状态机:
const handleSSEMessage = (msg: SSEMessage) => {
switch (msg.type) {
// ══════════════════════ 步骤0→1:标题生成完成 ══════════════════════
case 'TITLES_GENERATED':
currentPhase.value = 'TITLE_SELECTING' // 切换到标题选择界面
titleOptions.value = msg.titleOptions || [] // 存储标题方案
isCreating.value = false // 停止加载动画
break
// ══════════════════════ 步骤1→2:大纲流式输出(核心!逐字渲染)══════════════════════
case 'AGENT2_STREAMING':
currentPhase.value = 'OUTLINE_GENERATING'
isOutlineStreaming.value = true
outlineRaw.value += msg.content || '' // ⭐ 追加拼接!不是替换!
scrollToBottom() // 自动滚到底部
break
// ══════════════════════ 步骤2→3:大纲生成完成 ══════════════════════
case 'OUTLINE_GENERATED':
currentPhase.value = 'OUTLINE_EDITING' // 切换到大纲编辑界面
outline.value = msg.outline || []
isCreating.value = false
break
// ══════════════════════ 步骤3:正文流式输出(核心!)══════════════════════
case 'AGENT3_STREAMING':
currentPhase.value = 'CONTENT_GENERATING'
currentStep.value = 2
isStreaming.value = true
article.value.content += msg.content || '' // ⭐ 同样追加拼接
scrollToBottom()
break
// ══════════════════════ 步骤4:配图需求分析完成 ══════════════════════
case 'AGENT4_COMPLETE':
currentStep.value = 3
totalImages.value = msg.imageRequirements?.length || 5
break
// ══════════════════════ 步骤5:单张配图完成 ══════════════════════
case 'IMAGE_COMPLETE':
imageCount.value++
imageProgress.value = Math.round((imageCount.value / totalImages.value) * 100)
break
// ══════════════════════ 步骤6:图文合成完成 ══════════════════════
case 'MERGE_COMPLETE':
article.value.fullContent = msg.fullContent // 最终完整文章
break
// ══════════════════════ 终态:全部完成 ══════════════════════
case 'ALL_COMPLETE':
currentPhase.value = 'COMPLETED'
currentStep.value = 6
isCompleted.value = true
break
// ══════════════════════ 终态:出错 ══════════════════════
case 'ERROR':
errorMessage.value = msg.message
errorVisible.value = true
currentPhase.value = 'INPUT' // 回退到初始状态
break
}
}第四步:UI实时更新——以大纲和正文为例
<!-- 大纲生成中 -->
<div v-else-if="currentPhase === 'OUTLINE_GENERATING'" key="outline-generating">
<div class="section-label">
<BulbOutlined />
<span>AI 正在规划文章大纲</span>
<span class="typing-cursor">|</span> <!-- 闪烁光标 -->
</div>
<!-- 大纲列表:从 outlineRaw 实时解析 -->
<div v-if="parsedOutline.length > 0" class="outline-list">
<div v-for="item in parsedOutline" :key="item.section" class="outline-item fade-in">
<div class="outline-title">{{ item.section }}. {{ item.title }}</div>
<ul class="outline-points">
<li v-for="(point, idx) in item.points" :key="idx">{{ point }}</li>
</ul>
</div>
</div>
</div>parsedOutline 计算属性——支持不完整JSON的增量解析
const parsedOutline = computed<OutlineItem[]>(() => {
if (!outlineRaw.value) return []
try {
// 优先尝试完整 JSON 解析
const parsed = JSON.parse(outlineRaw.value)
if (parsed && Array.isArray(parsed.sections)) {
return parsed.sections
}
return []
} catch {
// ⭐ 关键:JSON 不完整时(正在传输中),
// 截取最后一个完整的对象进行部分渲染
// 这样用户能看到"逐渐长出来"的大纲
const sectionsMatch = outlineRaw.value.match(/"sections"\s*:\s*\[/)
// ... 部分解析逻辑 ...
}
})正文的流式展示:
<!-- 正文预览(流式输出)-->
<div v-if="article.content" class="content-preview">
<!-- marked 将 Markdown 实时转为 HTML -->
<div v-html="markdownToHtml(article.content)" class="markdown-body"></div>
<span v-if="isStreaming" class="typing-cursor">|</span>
</div>创建文章任务执行完成,返回多个可选标题,用户确认标题并根据需要输入补充描述,调用 ConfirmTitle 方法。
func (s *ArticleService) ConfirmTitle(taskID, mainTitle, subTitle string, userDescription *string, userID int64, isAdmin bool) error
1. 根据 taskID 查询 article 表获取文章数据
2. 确认是普通/VIP 用户且 userID 与数据库中 article 无误做权限校验
3. 根据步骤1得到的文章数据校验此刻阶段是否为 TITLE_SELECTING
4. 更新文章标题和用户描述信息 mainTitle、subTitle、userDescription 至 article 底表
5. 异步执行阶段2:生成大纲 ExecutePhase2Async
接下来详细介绍 ExecutePhase2Async 方法。
func (s *ArticleService) ExecutePhase2Async(taskID string)
1. 根据 taskID 查询 article 表获取文章数据
2. 更新文章状态信息为 OUTLINE_GENERATING
3. 创建 ArticleState 结构体用于后续 agent 层传输数据,需要传输的数据主要有五个:taskID、style、userDescription、phase、title,其中 title 包括 mainTitle 和 subTitle。
4. 读取配置信息确认走多智能体编排逻辑 ExecutePhase2,该方法是涉及回调函数,下面详细介绍了该回调函数的设计思想。
5. 判断生成大纲方法 ExecutePhase2 是否执行成功:
5.1. 如果不成功,需要将文章状态改成 FAILED,并且向前端推送错误消息并完成 SSE 客户端注销。
5.2. 如果成功,保存大纲到数据库底表,更改文章阶段为 OUTLINE_EDITING,向前端推送大纲完成信息。
闭包函数的回调思想,在当前 service 层需要两个参数,一个是当前层就可以获得的 taskID,另一个是此时不能立刻获得的 message。以闭包的形式不断下沉到更底层直到获取到 message,然后在那个地方直接执行该闭包函数就等同于在 service 层传入 taskID 和 message 参数后执行的效果。所以回调的思想就是在浅层(这里指 service 层这种更接近前端的层)的方法需要的参数往往在深层(本例子深入到了 agent 层)才能获取,所以不断的下沉直到获取所需的参数并执行。
本例子中从 service/article.go 开始调用 s.orchestrator.ExecutePhase2(ctx, state, func(message string) {
s.handleStreamMessage(taskID, message)
}) ,可以看到闭包方法需要一个名为 message 的参数才能调用 handleStreamMessage 方法,而 message 还在更深层等待着。先下沉到 agent/orchestrator.go 文件中 ExecutePhase2 方法作为起点,然后经过 agent/context/stream_handler.go 文件中的 WithStreamHandler 方法保存到 ctx (这段逻辑不属于下沉,而是为了传递回调函数方便采用的装箱手段),然后再下沉到 agent/agents/outline_generator.go 文件中的 Execute 方法,再通过 agent/context/stream_handler.go 文件中的 GetStreamHandler 方法拿出 ctx(同样,这段逻辑也不属于下沉,方便传递的拆箱手段) ,最后下沉到 agent/agents/outline_generator.go 文件中的 callLLMWithStreaming 方法中才真正的执行了生成 message 的业务逻辑,生成好后在此直接传入 message 参数调用闭包函数,进而完成本该在 service 层执行的闭包 func 下的 handleStreamMessage 方法。handleStreamMessage 方法根据参数 taskID 和 message 将 AI 内容通过 SSE 写入 channel,然后前端调用 GetProgress 方法返回给浏览器,完成 AI 大纲生成的完整调用。
问1:在整个回调过程中可以发现使用了 Context 把 streamHandler 回调函数进行传递,这样做是为什么呢?不能通过形参的方式显式传递吗?
答:streamHandler 整个的回调链是很深的,梳理一下 ExecutePhase2 -> outlineGenerator.Execute -> callLLMWithStreaming 整个流程。用 Context 可以让每一层传递无感知的进行透传,而不使用 Context,采用显式传递 streamHandler 参数就需要中间层的每个方法签名都加入这个参数,显得很臃肿。
接下来详细介绍 ExecutePhase2 方法。
func (o *ArticleAgentOrchestrator) ExecutePhase2(ctx context.Content, state *model.ArticleState, streamHandler func(string)) error
1. 将回调函数 streamHandler 设置到 context 中
2. 调用大纲生成 Agent 的执行方法 Execute
3. 向前端推送生成的大纲信息 sendMessage
func (a *OutlineGeneratorAgent) Execute(ctx context.Context, state *model.ArticleState) error
1. 构建 prompt,包括主标题、副标题、用户描述部分、文章风格
2. 从 context 中获取回调函数 streamHandler
3. 调用 callLLMWithStreaming 方法根据 prompt 和 streamHandler 参数得到 AI 生成的大纲内容
4. 向共享传输结构体 ArticleState 中填充大纲内容字段
生成完大纲内容后需要确认大纲,前端调用接口方法 ConfirmOutline
func (h *ArticleHandler) ConfirmOutline(c *gin.Context)
1. 反序列化前端请求结构体
2. 基于 Redis Session 获取当前用户
3. 判断用户是否是管理员
4. 调用业务逻辑层 ConfirmOutline 方法确认大纲
接下来详细看一下 service 层的 ConfirmOutline 方法是如何实现的。
func (s *ArticleService) ConfirmOutline(taskID string, outline []model.OutlineSection, userID int64, isAdmin bool) error
1. 根据 taskID 查询文章数据
2. 根据 userID 和 isAdmin 进行用户信息与权限校验
3. 校验当前文章阶段是否为 OUTLINE_EDITING
4. 更新文章大纲内容重新写回文章底表
5. 异步执行阶段3:生成正文+配图 ExecutePhase3Async
阅读学习 ExecutePhase3Async 异步方法的实现逻辑。
func (s *ArticleService) ExecutePhase3Async(taskID string)
1. 根据 taskID 查询文章数据
2. 更新文章阶段为 CONTENT_GENERATING
3. 创建文章状态共享传输对象 ArticleState,并设置任务ID TaskID、文章风格 Style、文章创作所处阶段 Phase、配图方式 EnabledImageMethods、文章标题 Title、文章大纲 Outline。
4. 读取配置确认走多智能体编排逻辑调用 ExecutePhase3 方法,该方法同样是回调方法。
5. 判断生成文章正文+配图方法 ExecutePhase3 是否执行成功:
5.1. 如果不成功,需要将文章状态改成 FAILED,并且向前端推送错误消息并完成 SSE 客户端注销。
5.2. 如果成功,保存内容到数据库底表,更改文章阶段为 ALL_COMPLETE,向前端推送大纲完成信息。
接下来详细阅读 ExecutePhase3 方法是如何实现的?
func (o *ArticleAgentOrchestrator) ExecutePhase3(ctx context.Content, state *model.ArticleState, streamHandler func(string)) error
1. 将回调函数 streamHandler 设置到 context 中
2. 生成正文智能体 contentGenerator
2.1. 调用 Execute 方法流式生成正文(策略模式+回调函数实现流式生成+推送的逻辑)
2.2. 调用 sendMessage 向前端推送生成的正文数据和 AGENT3_COMPLETE 状态信息
3. 分析配图需求智能体 imageAnalyzer
3.1. 调用 Execute 方法生成配图指南与需求
3.2. 调用 sendMessage 向前端推送配图需求 ImageRequirements 信息和 AGENT4_COMPLETE 状态信息
4. 并行生成配图智能体 parallelImageGenerator
4.1. 调用 Execute 方法并行生成配图
4.2. 调用 sendMessage 向前端推送配图 Images 数据和 AGENT5_COMPLETE 状态信息
5. 调用图文合并 contentMerger 的 Execute 方法生成最终的文章
6. 调用 sendMessage 向前端推送生成的最终文章和 MERGE_COMPLETE 状态信息
接下来就详细看一下这几个至关重要的 Execute 方法的内部逻辑。
先来看第一个 contentGenerator 结构体实现的 Execute 方法
func (a *contentGenerator) Execute(ctx context.Context, state *model.ArticleState) error
1. 创建日志记录+ defer 保存日志记录
2. 构建创作正文的 prompt,填充 mainTitle、subTitle、outline 以及 style。
你是一位资深的内容创作者,擅长撰写优质文章。
根据以下大纲,创作文章正文:
主标题:{mainTitle}
副标题:{subTitle}
大纲:
{outline}
要求:
1. 内容要充实,每个章节300-400字
2. 语言流畅,富有感染力
3. 适当使用金句,增强可读性
4. 添加过渡句,确保逻辑连贯
5. 使用 Markdown 格式,章节使用 ## 标题
请直接返回 Markdown 格式的正文内容,不要有其他内容。3. 从 context 中获取回调函数 streamHandler
4. 调用 callLLMWithStreaming 方法根据 prompt + streamHandler 完成 AI 回复和向前端推送的逻辑
5. 填充文章共享传输对象 ArticleState 的 Content 字段,填充日志记录对象的 Status 和 OutputData 字段
接下来看第二个 ImageAnalyzerAgent 结构体实现的 Execute 方法
func (a *ImageAnalyzerAgent) Execute(ctx content.Context, state *model.ArticleState) error
1. 创建日志记录+ defer 保存日志记录
2. 构建可用配图方式说明
3. 构建各配图方式的详细使用指南
4. 构建配图需求分析 prompt,填充 mainTitle、content、availableMethods、methodUsageGuide
你是一位专业的新媒体编辑,擅长为文章配图。
根据以下文章内容,分析配图需求,并在正文中插入图片占位符:
主标题:{mainTitle}
正文:
{content}
【重要】可用的配图方式(请严格只从以下方式中选择,禁止使用未列出的方式):
{availableMethods}
各配图方式的使用要求:
{methodUsageGuide}
通用要求:
1. 识别需要配图的位置(封面、关键章节、段落之间等)
2. 建议配图数量: 3-5张
3. **在正文中插入占位符**:使用格式 {{IMAGE_PLACEHOLDER_N}},其中 N 为配图序号(1, 2, 3...)
- 封面图占位符 {{IMAGE_PLACEHOLDER_1}} 放在文章最开头(正文第一行之前)
- 其他配图占位符可以放在任意合适位置(章节标题后、段落之间、列表项后等)
- 占位符必须独占一行
4. **imageSource 字段必须且只能是上述可用配图方式之一,不要使用其他值**
5. placeholderId 必须与正文中插入的占位符完全一致
6. position=1 为封面图
请直接返回 JSON 格式,不要有其他内容:
{
"contentWithPlaceholders": "{{IMAGE_PLACEHOLDER_1}}\n\n## 章节标题1\n\n正文内容...\n\n{{IMAGE_PLACEHOLDER_2}}\n\n## 章节标题2\n\n更多正文内容...\n\n{{IMAGE_PLACEHOLDER_3}}\n\n...",
"imageRequirements": [
{
"position": 1,
"type": "cover",
"sectionTitle": "",
"imageSource": "NANO_BANANA",
"keywords": "",
"prompt": "A modern minimalist illustration of AI technology concept, featuring abstract neural network patterns with blue and purple gradient colors, clean design suitable for article cover, 16:9 aspect ratio",
"placeholderId": "{{IMAGE_PLACEHOLDER_1}}"
},
{
"position": 2,
"type": "section",
"sectionTitle": "章节标题1",
"imageSource": "PEXELS",
"keywords": "business success teamwork office",
"prompt": "",
"placeholderId": "{{IMAGE_PLACEHOLDER_2}}"
},
{
"position": 3,
"type": "section",
"sectionTitle": "章节标题2",
"imageSource": "MERMAID",
"keywords": "",
"prompt": "flowchart TB\n A[用户请求] --> B[负载均衡]\n B --> C[应用服务器]",
"placeholderId": "{{IMAGE_PLACEHOLDER_3}}"
}
]
}5. 根据 prompt 生成 AI 正文和配图
6. 填充文章共享传输对象 ArticleState 的 ContentWithPlaceholders、ImageRequirements 字段,填充日志记录对象的 Status、OutputData 字段
接下来看第三个 ParallelImageGenerator 结构体实现的 Execute 方法
func (g *ParallelImageGenerator) Execute(ctx context.Context, state *model.ArticleState) error
1. 从 Context 中获取回调函数 streamHandler
2. 对 imageRequirements 按 imageSource 进行分组
在生成的 imageRequirements 中不同章节间采用的生成图片的方式源都不一样,为了更好的并行执行不同章节的图片生成,提前按照 imageSource 进行分组
3. 调用 executeParallel 方法并行执行不同类型的图片生成
4. 按章节顺序进行排序
5. 填充文章共享传输对象 ArticleState 的 Images 字段
详细看一下 executeParallel 方法的内部逻辑
func (g *ParallelImageGenerator) executeParallel(ctx context.Context, groupedBySource map[string][]model.ImageRequirement, streamHandler agentContext.StreamHandler) []model.ImageResult
该方法的核心逻辑是不同 imageSource 类型并行执行,同一类型内部串行执行。
使用 WaitGroup 等待所有 goroutine 完成,使用 Mutex 保护共享的结果切片。WaitGroup 的详细使用方法请见之前写过的文章。
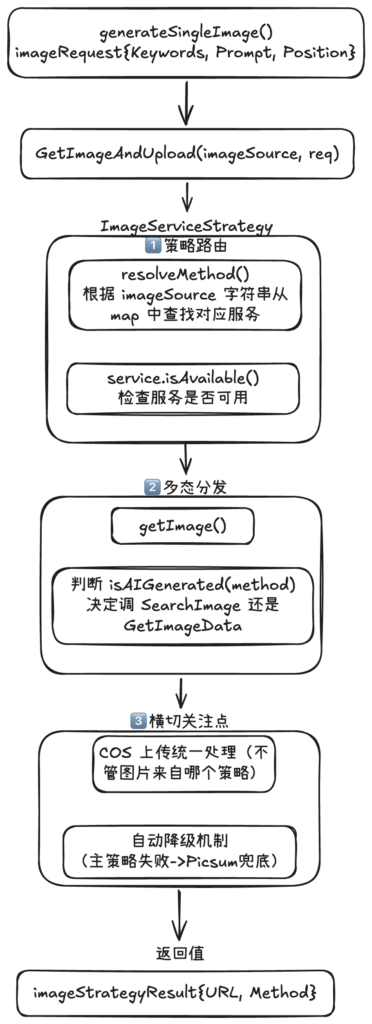
该方法中主要看如何生成单张图片的 generateSingleImage 方法
func (g *ParallelImageGenerator) generateSingleImage(ctx context.Context, req model.ImageRequirement, streamHandler agentContext.StreamHandler) *model.ImageResult
1. 创建图片请求对象
2. 调用 GetImageAndUpload 方法使用策略模式获取图片并统一上传到 COS
3. 创建配图结果
4. 调用回调函数推送单张图片完成
这里的核心是 GetImageAndUpload 方法
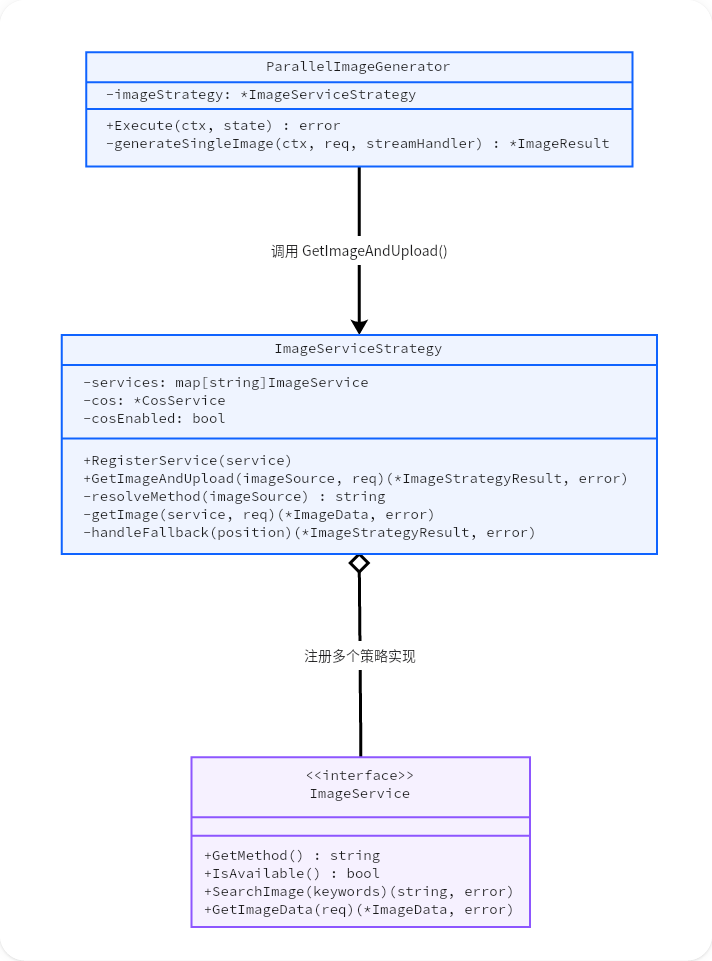
func (s *ImageServiceStrategy) GetImageAndUpload(imageSource string, req *model.ImageRequest) (*model.ImageStrategyResult, error)
策略模式体现在根据选择的 imageSource 选择对应的 ImageService
ImageServiceStrategy 策略模式完整解析
1. 策略模式全景架构图

2. 策略模式的四要素在本项目中的映射
| 策略模式要素 | 经典定义 | 本项目对应 |
| 策略接口 | 定义所有方法的公共接口 | /service/image_service.go 文件的 ImageService 接口,声明了四个方法:GetMethod、IsAvailable、SearchImage、GetImageData |
| 具体策略 | 接口的具体实现类 | Pexels、NanoBanana、Mermaid、Iconify、EmojiPack、SVGDiagram、Picsum(7个) |
| 上下文 | 持有策略引用,委托给策略执行 | /service/image_strategy.go 文件的 ImageServiceStrategy 类(含服务注册表+COS上传+COS是否可用的降级逻辑) |
| 客户端 | 使用上下文来选择调用策略 | /agent/parallel/image_generator.go 文件ParallelImageGenerator 类的 generateSingleImage 方法 |
接口 ImageService 的四个方法中的 SearchImage 和 GetImageData 两个方法覆盖了两类不同的图片来源方式:
| 类型 | 代表服务 | 核心方法 | 输入 | 输出 |
| 检索类(Search) | Pexels、Iconify、EmojiPack、Picsum | SearchImage | keywords->URL | 图片URL |
| 生成类(Generate) | NanoBanana、Mermaid、SVGDiagram | GetImageData | prompt->bytes | 图片二进制/SVG |
3. 上下文层——ImageServiceStrategy 的核心设计
这是策略模式中最重要的部分。它不仅是简单的“持有策略并调用”,而是做了三件额外的事情:
No responses yet